AWS
0 AWS 产品
计算
- Amazon EC2
云中的虚拟服务器 - Auto Scaling
- Amazon VPC
隔离的云资源 - Elastic Load Balancing
联网
- Amazon VPC
隔离的云资源 - AWS Direct Connect
AWS 的专用网络连接 - Amazon Route 53
可扩展的域名系统 (DNS) - Elastic Load Balancing
存储和内容分发
- Amazon S3
可扩展的云存储 - Amazon Glacier
云中的低成本归档存储 - Amazon EBS
EC2 块存储卷 - AWS Storage Gateway
将内部 IT 环境与云存储相集成 - Amazon CloudFront
全球内容分发网络 (CDN) - AWS Import/Export
大容量数据传输
数据库
- Amazon RDS
适用于 MySQL、Oracle、SQL Server 和 PostgreSQL 的管理型关系数据库服务 - Amazon DynamoDB
快速、可预测、高可扩展的 NoSQL 数据存储 - Amazon Redshift
快速、功能强大的完全管理型 PB 级数据仓库服务 - Amazon ElastiCache
基于内存的缓存服务
分析
- Amazon Kinesis
实时数据流处理 - Amazon Redshift
快速、功能强大的完全管理型 PB 级数据仓库服务 - Amazon EMR
托管的 Hadoop 框架 - AWS Data Pipeline
适用于周期性数据驱动工作流的编排服务
应用程序服务
- Amazon CloudSearch
托管的搜索服务 - Amazon AppStream
低延迟应用程序流媒体传输 - Amazon SES
电子邮件发送服务 - Amazon SQS
消息队列服务 - Amazon SNS
推送通知服务 - Amazon SWF
用于协调应用程序组件的工作流服务 - Amazon FPS
基于 API 的付款服务 - Amazon Elastic Transcoder
易用型可扩展媒体转码
部署与管理
- AWS Elastic Beanstalk
AWS 应用程序容器 - AWS OpsWorks
DevOps 应用程序管理服务 - AWS CloudFormation
AWS 资源创建模板 - AWS CloudTrail
用户活动与变更追踪 - Amazon CloudWatch
资源与应用程序监控 - AWS Identity and Access Management (IAM)
可配置的 AWS 访问控制 - AWS CloudHSM
有助于实现监管合规性的基于硬件的密钥存储 - AWS 管理控制台
基于 Web 的用户界面 - AWS 命令行界面
管理 AWS 服务的统一工具
移动服务
- Amazon Cognito
用户身份和数据同步 - Amazon Mobile Analytics
快速、安全的应用程序使用情况分析 - Amazon SNS
跨越多种平台发送通知、更新和促销信息 - AWS 移动软件开发工具包
快速轻松开发高质量移动应用程序
应用程序
- Amazon WorkSpaces - 云中的虚拟桌面
- Amazon Zocalo - 安全的企业文档存储和共享
1 使用 AWS S3
S3 是 Simple Storage Service 的缩写,是 AWS 提供的云存储服务,价格公道、服务稳定,因此被广泛应用在静态文件存储、内容备份、大数据分析领域。
基本概念
在使用 S3 前首先需要了解一些基本概念:
- 对象:即文件。
- Bucket:官方翻译为存储桶,是在网络存储服务中广泛使用的一个概念,通常用于区分文件所在区域,可以对比操作系统不同盘符来理解。
- AWS CLI:AWS 提供的控制台工具,aws-cli 是其在 PyPI 上注册的名字,shell 中的命令为
aws。 - AWS IAM:即 Identity and Access Management,是 AWS 的身份认证服务,用于对用户身份及资源进行授权管理,需要配置号已授权的 AWS 认证信息才可以使用其服务。
- S3 资源:S3 资源以
s3://bucket-name/开始。
基本操作
创建以及管理 Bucket
就像你首先需要有硬盘以及挂载盘符才能在本地操作文件一样,正式使用 S3 提供服务前你同样需要准备好 Bucket:
aws s3 mb s3://bucket-name
Bucket 名称必须唯一,并且应符合 DNS 标准:可以包含小写字母、数字、连字符(-)和点号(.), 只能以字母或数字开头和结尾,连字符或点号后不能跟点号。
想要列出以创建的 Bucket 可以使用 ls 命令:
$ aws s3 ls
CreationTime Bucket
------------ ------
2015-11-11 11:11:11 my-bucket
2015-11-11 11:11:11 my-bucket1
删除空 Bucket 可以使用 aws s3 rb s3://bucket-name,非空 Bucket 需要加上 --force
命令,这一点对于管理文件对象也是一样。
mb、rb 命令分别是 MakeBucket 和 RemoveBucket 的缩写。
操作文件
S3 的服务基于文件对象,提供了类似 Linux 环境下的文件访问操作:
aws s3 ls s3://bucket-name[/folder]/
aws s3 cp s3://bucket-name/file s3://bucket-name[/folder]/
aws s3 mv s3://bucket-name/file s3://bucket-name[/folder]/
aws s3 rm s3://bucket-name/file
aws s3 rm s3://bucket-name[/folder]/ --recursive
操作文件的方式基本上和 Linux 环境类似,--recursive 用于递归调用,类似 Linux 命令的
-r 参数。
同步本地文件、目录
AWS CLI 还提供了一个本地文件同步命令 sync:
aws s3 sync local_dir s3://my-bucket/MyFolder
sync 会递归地将本地文件复制到 S3 Bucket 中,如存在重名文件则覆盖处理。
如果需要像同步盘一样删除已不存在的文件可以加上 --delete 命令。
sync 还可以通过 --exclude 和 --include 来指定不同步的目录,以及不同步的目录中的例外。
权限控制
默认情况下,所有 Amazon S3 资源都是私有的,包括存储桶、对象和相关子资源(例如,lifecycle 配置和 website 配置)。只有资源拥有者,即创建该资源的 AWS 账户可以访问该资源。资源拥有者可以选择通过编写访问策略授予他人访问权限
Amazon S3 提供的访问策略
- 基于资源的策略 ------- 存储桶策略和访问控制列表 (ACL – 注:每个存储桶和对象都有关联的 ACL)
- 基于用户策略 ------ 使用 IAM 管理,IAM 用户必须拥有两种权限:一种权限来自其父账户,另一种权限来自要访问的资源的拥有者 AWS 账户。
实际应用
每天凌晨备份 Postgres 数据库
pg_dump -Fc --no-owner bxzz_exercise > /tmp/tmp.pgdump && aws s3 cp tmp.pgdump s3://filebackup/pg/$(date +%Y/%m/%d).pgdump
crontab 设置:
0 2 * * * pg_dump -Fc --no-owner bxzz_exercise > /tmp/tmp.pgdump && aws s3 cp tmp.pgdump s3://filebackup/pg/$(date +\%Y/\%m/\%d).pgdump
将 S3 当作同步盘
检测到文件变动时触发:
aws s3 sync . s3://my-bucket/MyFolder --exclude '*.txt' --include 'MyFile*.txt' --exclude 'MyFile?.txt'
2 Amazon IAM(身份及访问管理)
IAM enables you to control who can do what in your AWS account.
-
存储桶策略示例
创建存储桶后需要创建个 IAM 用户和关联下权限
创建对某个存储桶有所有权限实例
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets"
],
"Resource": "arn:aws-cn:s3:::*"
},
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws-cn:s3:::backet-name/*"
]
}
]
}
注:Amazon 资源名称 (ARN) 和 AWS 服务命名空间
arn:partition:service:region:account-id:resource
partition: 资源所处的分区。对于标准 AWS 区域,分区是 aws。如果资源位于其他分区,则分区是 aws-partitionname。例如,位于 中国(北京) 区域的资源的分区为 aws-cn。
3 EC2
重启与停止以及终止之间的区别
| 性能 | 重启 | 停止 / 启动(仅限 Amazon EBS 支持的实例) | 终止 |
|---|---|---|---|
| 主机 | 实例保持在同一主机上运行 | 实例在新主机上运行 | 无 |
| 私有和公有 IP 地址 | 这些地址保持不变 | EC2-Classic:实例获得新的私有和公有 IP 地址 EC2-VPC:实例保留其私有 IP 地址。实例获取新的公有 IP 地址,除非它具有弹性 IP 地址 (EIP)(该地址在停止 / 启动过程中不更改)。 | 无 |
| 弹性 IP 地址 (EIP) | EIP 保持与实例关联 | EC2-Classic:EIP 不再与实例关联,EC2-VPC:EIP 保持与实例关联 | EIP 不再与实例关联 |
| 实例存储卷 | 数据保留 | 数据将擦除 | 数据将擦除 |
| 根设备卷 | 卷将保留 | 卷将保留 | 默认情况下将删除卷 |
| 记账功能 | 实例计费小时不更改 | 实例的状态一旦变为 stopping,就不再产生与该实例相关的费用。每次实例从 stopped 转换为 pending 时,我们都会启动新的实例计费小时 | 实例的状态一旦变为 shutting-down,就不再产生与该实例相关的费用 |
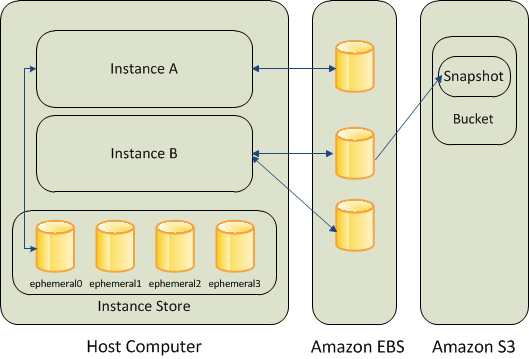
存储
- Amazon EBS
- Amazon EC2 实例存储卷(停止实例时,会删除数据,只有部分实例有)
- Amazon S3
4 AWS VPC
VPC 中几个概念
VPC
- VPC 即 virtual private cloud,是个虚拟的局域网
- AWS 云中的一个私有的、隔离的部分
- 可自定义的虚拟网络拓扑
子网
VPC 是为了将你的所有服务与外界隔离开来,但是范围比较大,如果你的局域网内部还需要进一步的网络划分,那么需要设置子网。子网位于 VPC 内部。
路由器
这个页面上没有
路由表
路由表创建在 VPC 上,创建时需要选择一个对应的 VPC
在 VPC 内创建的所有路由表都会包含一条到达该 VPC 的路由项,而且不能删除。可以在此基础上再添加新路由项,如 Internet 网关。
主要功能是将消息从 VPC 内发到 VPC 外,不是子网间使用的
Internet 网关
如果要上网,Internet 网关是必须的,创建好后还要将其关联到路由表。点击做导航“路由表”,在右面的列表选中一项,在下方的路由选项卡中可以点击“编辑”添加 Internet 网关
安全组
安全组是入站规则与出站规则的集合。安全组同样是建立在 VPC 上的,创建时需要指定 VPC
VPC 的地区
- 区域
- 相互隔离的地区区域
- 可用区 (AZ)
- 数据中心
AWS 有 10 个区域、每个区域有多个可用区
VPC 规划
- 考虑将来的扩展
- VPC 可以从 /16 到 /28
- CIDR 不可修改
- 考虑将来是否需要与公司网络建立链接
- 重复的 IP 地址空间 = 未来的痛苦
5 AWS 客户端
AWS CLI
AWS CLI 是 AWS 提供的命令行工具,使用 Python 开发支持 Python 2.6.5 以上绝大多数 Python 版本。
安装
在 Unix/Linux 平台安装 AWS CLI 建议使用 pip:
pip install aws-cli
注意这里是"aws-cli"而不是"aws"
个人还推荐一个叫做 saws 的 aws-cli 封装包,提供了强大的命令补全功能:
pip install saws
配置
在使用 aws-cli 之前,你首先需要配置好个人身份信息以及偏好区域。 配置个人身份信息前还需要注册 AWS ISM,并为自己的身份授予对应的权限。
AWS 的配置文件分 config 和 credentials,默认存储在 ~/.aws 目录中,格式如下:
# ~/.aws/credentials
[default]
aws_access_key_id=XXXXXXXXXXXXXXXXXXXX
aws_secret_access_key=XXXXXXXXXXXXXXXXXXXX
[dev]
aws_access_key_id=XXXXXXXXXXXXXXXXXXXX
aws_secret_access_key=XXXXXXXXXXXXXXXXXXXX
[s3]
aws_access_key_id=XXXXXXXXXXXXXXXXXXXX
aws_secret_access_key=XXXXXXXXXXXXXXXXXXXX
# ~/.aws/config
[default]
region=cn-north-1
output=json
[user1]
region=us-west-2
output=text
参数解释:
aws_access_key_id:AWS 访问密钥。aws_secret_access_key:AWS 私有密钥。aws_session_token:AWS 会话令牌。只有在使用临时安全证书时才需要会话令牌。region:AWS 区域。output:输出格式(json、text 或 table)
环境变量
AWS CLI 支持以下变量:
AWS_ACCESS_KEY_ID:AWS 访问密钥。AWS_SECRET_ACCESS_KEY:AWS 私有密钥。访问和私有密钥变量会覆盖证书和 config 文件中存储的证书。AWS_SESSION_TOKEN:会话令牌。只有在使用临时安全证书时才需要会话令牌。AWS_DEFAULT_REGION:AWS 区域。如果设置,此变量会覆盖正在使用的配置文件的默认区域。AWS_DEFAULT_PROFILE:要使用的 CLI 配置文件的名称。可以是存储在证书或 config 文件中的配置文件的名称,也可以是 default,后者使用默认配置文件。AWS_CONFIG_FILE:CLI config 文件的路径。
命令行参数
参考:AWS 官方文档
使用
aws ec2 describe-instances --profile dev
aws ec2 describe-instances --profile default
aws s3api put-object --body /root/start.sh --bucket bucket-name --key "start.sh" --profile s3
saws 工具
saws 是 aws-cli 封装包
S3
上传文件
前提:AWS 的配置中的访问密钥对 S3 的某 bucket-name 有权限
输入 saws 后输入
saws>aws s3api put-object --body /root/start.sh --bucket bucket-name --key "start.sh"
{
"ETag": "\"2bdd5dd11b4273cfb0a807539325xxx\""
}
下载文件
前提:AWS 的配置中的访问密钥对 S3 的某 bucket-name 有权限
输入 saws 后输入
saws>aws s3api get-object --bucket bucket-name --key "start.sh" /root/start.sh2"
{
"AcceptRanges": "bytes",
"ContentType": "binary/octet-stream",
"LastModified": "Thu, 13 Oct 2016 02:55:48 GMT",
"ContentLength": 241,
"ETag": "\"2bdd5dd11b4273cfb0a807539325xxx\"",
"Metadata": {}
}
S3cmd
下载及配置
在 Linux 上 安装 s3 客户端
下载后解压进入到目录中
连接 AWS S3 时可以通过s3cmd --config进行配置,连接本地自有的存储可以配置如下
在当前用户的家目录下创建 .s3cfg 文件、(也是 s3cmd 默认配置文件路径、),并填入以下内容:
[default]
access_key = XXXXXXXXXXXXXXXXXXXX
secret_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
host_base = 10.20.144.2
host_bucket = 10.20.144.2:80/%(bucket)
use_https = False
# 签名是 V2 的话设置为 True
signature_v2 = True
使用 S3cmd
配置完 S3cmd 就可以通过它来使用对象存储了。
对象存储中有两个非常重要的概念,bucket 和 object。object 对应需要存储的文件,而 bucket 作为 object 的存储空间。所以对象存储的操作主要涉及到的就是对 bucket 和 object 的操作。
操作 bucket
- 列举 bucket
# s3cmd ls
以列举当前的 bucket 为例:
# s3cmd ls 2015-08-12 03:56 s3://test-bucket_1- 创建 bucket
# s3cmd mb s3://BUCKET以创建名为 test_bucket_1 的 bucket 为例:
# s3cmd mb s3://test-bucket_1 Bucket 's3://test-bucket_1/' created- 删除 bucket
# s3cmd rb s3://BUCKET以删除我们刚创建的 test_bucket_1 为例:
# s3cmd rb s3://test-bucket_1 Bucket 's3://test-bucket_1/' removed- 列举 bucket
操作 object
需要在 S3 中存储的文件在对象存储中被称为 object。为了说明上传 object 的过程,首先我们来创建一个用来上传的文件 test.txt (也就是一个 object), 并写入 samplecontent 作为文件的内容:
准备文件
# cat test.txt samplecontent创建 bucket
# s3cmd mb s3://test-bucket_2 Bucket 's3://test-bucket_2/' created上传 object
s3cmd put FILE [FILE...] s3://BUCKET[/PREFIX]以上传刚创建的 test.txt 文件到 test_bucket_2 bucket 为例:
# s3cmd put test.txt s3://test-bucket_2 WARNING: Module python-magic is not available. Guessing MIME types based on file extensions. test.txt -> s3://test-bucket_2/test.txt [1 of 1] 14 of 14 100% in 0s 20.59 kB/s 14 of 14 100% in 90s 0.16 B/s done- 列出 bucket 中 object
# s3cmd ls [s3://BUCKET[/PREFIX]]以列出当前 bucket 中的 object:
# s3cmd ls s3://test-bucket_2 2015-08-12 04:22 14 s3://test-bucket_2/test.txt- 下载 bucket 中 object
# s3cmd get s3://BUCKET/OBJECT LOCAL_FILE下载当前 bucket 中的文件 test.txt,并本地命名 localtest.txt:
# s3cmd get s3://test-bucket-2/test.txt localtest.txt s3://test-bucket-2/test.txt -> localtest.txt [1 of 1] s3://test-bucket-2/test.txt -> localtest.txt [1 of 1] 348 of 348 100% in 0s 10.58 kB/s done- 删除 bucket 中 object
# s3cmd del s3://BUCKET/FILENAME删除当前 bucket 中的 test.txt 对象:
# s3cmd del s3://test-bucket-2/test.txt File s3://test-bucket-2/test.txt delete- 拷贝 bucket 中 object
# s3cmd cp s3://BUCKET1/OBJECT1 s3://BUCKET2[/OBJECT2]拷贝对象,从一个 bucket 到另一个 bucket:
# s3cmd cp s3://test-bucket-2/test1.txt s3://test-bucket-1/test1.txt WARNING: Retrying failed request: /test1.txt () WARNING: Waiting 3 sec... File s3://test-bucket-2/test1.txt copied to s3://test-bucket-1/test1.tx- 获取 object 信息
# s3cmd info s3://BUCKET/OBJECT获取当前 object 的信息:
# s3cmd info s3://test-bucket-2/test1.txt s3://test-bucket-2/test1.txt (object): File size: 348 Last mod: Fri, 14 Aug 2015 02:02:37 GMT MIME type: text/plain MD5 sum: 4b49d7dd076b0b71e0eda307388fac57 SSE: NONE
其余使用请参见 S3cmd usage: S3cmd 使用手册